这篇就不多说了,前几日搞了个爬企查查的,今日再搞一个天眼查的,希望诸位从这两份源码上学到一些东西。
运行如下:
爬到数据如下:
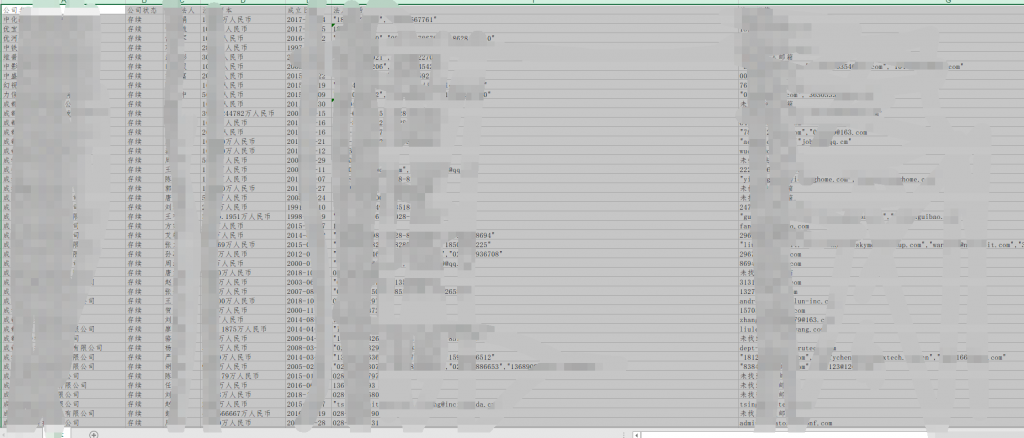
源码如下:
#-*- coding-8 -*-
import requests
import lxml
import sys
from bs4 import BeautifulSoup
import xlwt
import time
import urllib
def craw(url,key_word,x,new_num):
User_Agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
if x == 0:
re = 'https://www.tianyancha.com/search?key='+key_word
else:
re = 'https://www.tianyancha.com/search/p{}?key={}'.format(x-1,key_word)
headers = {
'Host': 'www.tianyancha.com',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': r'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Referer': re,#'https://www.tianyancha.com/search?key=%E5%B1%B1%E4%B8%9C%20%E7%A7%91%E6%8A%80',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': r'cookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookiecookie',
}
try:
response = requests.get(url,headers = headers)
if response.status_code != 200:
response.encoding = 'utf-8'
print(response.status_code)
print('ERROR')
soup = BeautifulSoup(response.text,'lxml')
except Exception:
print('请求都不让,这天眼查也搞事情吗???')
try:
com_all_info = soup.body.select('.mt74 .container.-top .container-left .search-block.header-block-container')[0]
com_all_info_array = com_all_info.select('.search-item.sv-search-company')
print('开始爬取数据,请勿打开excel')
except Exception:
print('好像被拒绝访问了呢...请稍后再试叭...')
try:
for i in range(new_num,len(com_all_info_array)):
try:
temp_g_name = com_all_info_array[i].select('.content .header .name')[0].text #获取公司名
temp_g_state = com_all_info_array[i].select('.content .header .tag-common.-normal-bg')[0].text #获取公司状态
temp_r_name = com_all_info_array[i].select('.content .legalPersonName.link-click')[0].text #获取法人名
temp_g_money = com_all_info_array[i].select('.content .info.row.text-ellipsis div')[1].text.strip('注册资本:') #获取注册资本
temp_g_date = com_all_info_array[i].select('.content .info.row.text-ellipsis div')[2].text.strip('成立日期:') #获取公司注册时间
try:
try:
temp_r_phone = com_all_info_array[i].select('.content .contact.row div script')[0].text.strip('[').strip(']') #获取法人手机号
except Exception:
temp_r_phone = com_all_info_array[i].select('.content .contact.row div')[0].select('span span')[0].text #获取法人手机号
except Ellipsis:
temp_r_phone = '未找到法人手机号'
try:
try:
temp_r_email = com_all_info_array[i].select('.content .contact.row div script')[1].text.strip('[').strip(']') #获取法人Email
except Exception:
temp_r_email = com_all_info_array[i].select('.content .contact.row div')[1].select('span')[1].text #获取法人Email
except Exception:
temp_r_email = '未找到法人邮箱'
# temp_g_desc = com_all_info_array[i].select('.content .match.row.text-ellipsis')[0].text #获取公司备注
g_name_list.append(temp_g_name)
g_state_list.append(temp_g_state)
r_name_list.append(temp_r_name)
g_money_list.append(temp_g_money)
g_date_list.append(temp_g_date)
r_phone_list.append(temp_r_phone)
r_email_list.append(temp_r_email)
# g_desc_list.append(temp_g_desc)
except Exception:
print(temp_g_name+"-信息不完整,>>>>跳过>>下一个")
except Exception:
print("这页有毒,换下一页")
if __name__ == '__main__':
global g_name_list
global g_state_list
global r_name_list
global g_money_list
global g_date_list
global r_phone_list
global r_email_list
# global g_desc_list
g_name_list=[]
g_state_list=[]
r_name_list=[]
g_money_list=[]
g_date_list=[]
r_phone_list=[]
r_email_list=[]
# g_desc_list=[]
key_word = input('请输入您想搜索的关键词:')
try:
new_num = int(input('请输入您想从第几页检索:'))-1
except Exception:
new_num = 0
try:
num = int(input('请输入您想检索的次数:'))+1
except Exception:
num = 6
try:
sleep_time = int(input('请输入每次检索延时的秒数:'))
except Exception:
sleep_time = 5
key_word = urllib.parse.quote(key_word)
print('正在搜索,请稍后')
for x in range(1,num):
url = r'https://www.tianyancha.com/search/p{}?key={}'.format(x,key_word)
# print(r'https://www.tianyancha.com/search/p{}?key={}'.format(x,key_word))
# url = r'https://www.tianyancha.com/search/p2?key=%E5%B1%B1%E4%B8%9C%20%E7%A7%91%E6%8A%80'
s1 = craw(url,key_word,x,new_num)
time.sleep(sleep_time)
workbook = xlwt.Workbook()
#创建sheet对象,新建sheet
sheet1 = workbook.add_sheet('天眼查数据', cell_overwrite_ok=True)
#---设置excel样式---
#初始化样式
style = xlwt.XFStyle()
#创建字体样式
font = xlwt.Font()
font.name = '仿宋'
# font.bold = True #加粗
#设置字体
style.font = font
#使用样式写入数据
print('正在存储数据,请勿打开excel')
#向sheet中写入数据
name_list = ['公司名字','公司状态','法定法人','注册资本','成立日期','法人电话','法人邮箱']#,'公司备注']
for cc in range(0,len(name_list)):
sheet1.write(0,cc,name_list[cc],style)
for i in range(0,len(g_name_list)):
print(g_name_list[i])
sheet1.write(i+1,0,g_name_list[i],style)#公司名字
sheet1.write(i+1,1,g_state_list[i],style)#公司状态
sheet1.write(i+1,2,r_name_list[i],style)#法定法人
sheet1.write(i+1,3,g_money_list[i],style)#注册资本
sheet1.write(i+1,4,g_date_list[i],style)#成立日期
sheet1.write(i+1,5,r_phone_list[i],style)#法人电话
sheet1.write(i+1,6,r_email_list[i],style)#法人邮箱
# sheet1.write(i+1,7,g_desc_list[i],style)#公司备注
#保存excel文件,有同名的直接覆盖
workbook.save(r"D:\wyy-tyc-"+time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) +".xls")
print('保存完毕~')PS:运行前请将自己的cookie放到26行那里。
PPS:爬不到数据?自己手动去过一遍验证码再试试看。
PPPS:爬到的是空数据?自己去手动搜索一下看看这个词搜不搜得到。
PPPPS:最后一句了…要是觉着有用的话…请关注并收藏此链接…我嘛…刚买了几年服务器….不出意外的话,几年内都在,请关注我…拜托拜托 ~
转载请注明:夜羽的博客 » 【原创】Python爬虫爬天眼查数据